Distribution Infrastructure
Several computing resources and infrastructure are used in the ARTIS data pipeline and distribution. We utilize cloud high-performance computing, cloud-based storage, and local machines to ingest and analyze aquatic resource trade data. These computing resources create the ARTIS database that is openly available for download at two access points:
- KNB data repository (recommended for bulk access)
- ARTIS dataset - https://doi.org/10.5063/F1CZ35N7
- ARTIS inputs and model - https://doi.org/10.5063/F1862DXT
- ARTIS website (in beta)
The schematic below depicts the ARTIS pipeline.
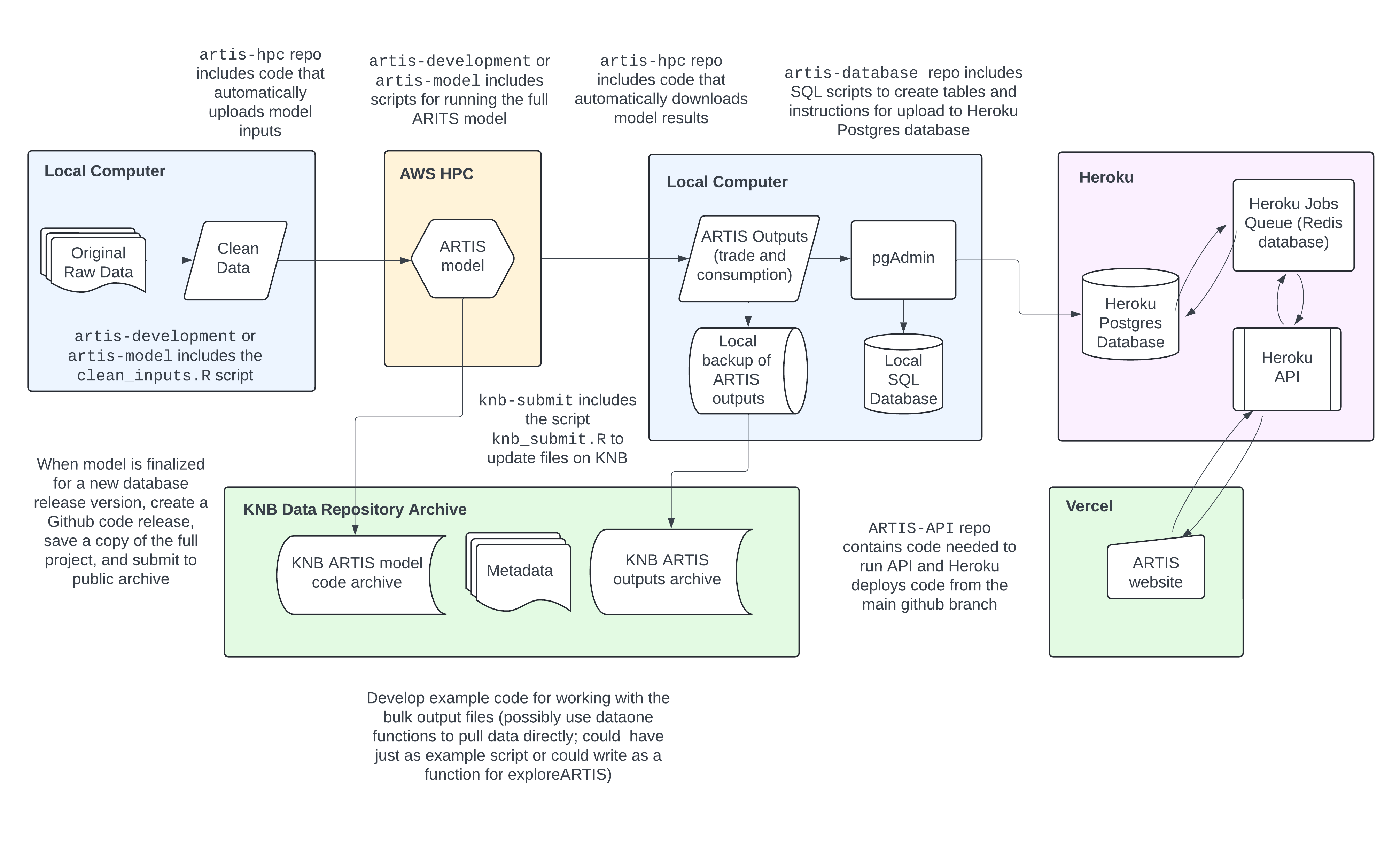
- Blue boxes – processes on local machines
- green boxes – access points
- yellow boxes – cloud HPC
- purple – cloud database storage
Pipeline component details:
- Original Raw Data
-
FAO global production, UN Comtrade, BACI, Sea Around Us, FishBase, and SeaLifeBase data contained in the
artis-model/model_inputs_raw/directory - Clean Data
-
Data cleaned and standardized in R and Python scripts and used in
artis-model/model_inputs/directory - ARTIS Model
- A model that estimates the aquatic resource trade flows and consumption
- ARTIS Outputs
-
Model results of trade flows and consumption tables stored in the ARTIS database found in the
artis-model/outputs/directory - pgAdmin
- Opensource application for managing PostgreSQL (a open source object-relational database system)
- KNB
- Knowledge Network for Biocomplexity data repository - database and model distribution point
- Heroku
- Cloud hosting platform supporting the ARTIS API - being migrated to Vercel
Github Code Repositories:
- artis-model
- Release version of model code link here
- artis-development
- Private development version of model code link here
- artis-hpc
- High-performance computing scripts for running model on Amazon Web Services link here
- artis-database
- Scripts for creating and maintaining the Postgres database in the cloud and locally link here
- artis-API
- Scripts for creating and maintaining the ARTIS API to website link here
- knb-submit
- Scripts for submitting data to the KNB data repository link here